#
BHive
The BHive (short: hive) provides a mechanism to store and transfer files over the network. It decouples storage of file content and hierarchical filesystem layout descriptions (trees). The mechanism is similar to how GIT stores files. File content is stored and identified by using the content's checksum.
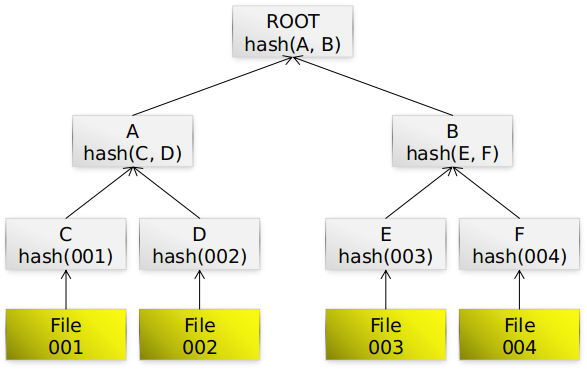
Here some properties of BHive:
- The BHive uses a Merkle Hash Tree to store data much like GIT does (similar technology is also used for implementing blockchains).
- Consistency of objects can be verified by calculating the checksum of the content and comparing it with the name of the file storing that content.
- BHive knows four different types of objects:
BLOB(any file content),TREE(a list ofBLOB,TREE,MREFentries),MREF(a reference to a to-be-nestedMANIFEST),MANIFEST(associates some meta-data with a rootTREE). - All known object types (except
MANIFEST) are stored using the exact same mechanism (ObjectDatabase). This means verifying the consistency of whole trees is as simple as verifying consistency of individual files. MANIFESTare stored in a separateManifestDatabase, this is to allow named storage and reference toMANIFEST, since they are the top-level entry point into the BHive. Most high level operations will requireManifest.Keyobjects as parameters.- BHive has a command line tooling to allow direct manipulation of local and remote hives:
io.bdeploy.bhive.cli.BHiveCli - BHive has a standalone server (using the above cli) which allows serving BHives without BDeploy.
- A
io.bdeploy.bhive.BHivedoes not expose API, useHive.Operationdefined in theio.bdeploy.bhive.oppackage to programmatically interact with a hive. Hive.Operationcan be implemented externally, to provide new functionality operating on a BHive from the outside.
#
BHive Tour
This chapter, along with the launch configuration available in the bhive project, will give a short tour around most of the functionality that bhive provides.
All launch configurations used will use a BHive target in a runtime workspace in the containing workspace (${workspace_loc}/runtime-hive) in case you want to have a look at it.
#
Import
Import is the act of digesting a folder recursively into a BHive storage. There are two important parameters: the source folder and the destination BHive. Since BHive creates an empty hive automatically in the destination, the target BHive directory is allowed to be non-existant. The source folder is not required to follow any rules at this low-level stage. BHive will simply digest any file found recursively. While doing so, it separates each files content from it's name. They are stored in separate locations (content as 'blob', name is stored in a 'tree' as 'pointer' to the 'blob' for this file's content).
Use the Hive-Import launch configuration to import a directory into the BHive. The launch will prompt for two things:
- The folder to import. You can choose any folder to import. The target hive is created automatically if it does not exists.
- The name (manifest key) of the imported tree. This name can be used to reference the imported tree later on. Note that a name:tag combination must be unique. Import will fail if the manifest key is already used.
Note that all BHive objects are immutable, meaning that there are never changes to any existing file. This is analogous to GIT. Manifests are not BHive objects but more special (they just reference a root tree BHive object). They are mutable in that labels can be added and removed from the manifest.
#
List
You can list the content of the BHive after importing by running the Hive-Manifest-List launch configuration. It will simply list all available manifests in the BHive.
#
Export
The inverse operation of an Import is (surprise) an Export, which means restoring a file/folder tree exactly as it was imported. The export will scan a manifest for 'tree' objects and write all 'blob' objects to the locations described there.
Run the Hive-Export launch configuration and specify a target folder (which may not yet exist). Next specify a manifest to export, use the key you specified during
Check the directory, you will notice that all files have been written back on disc, and the folder content is equal to the one imported.
#
Remote Serve
BHive provides a small embedded server which allows serving any number of local hives through HTTPS.
Run the Hive-Remote-Serve launch configuration to run the server, serving the BHive created with the Hive-Import application.
Note: the sample launch configurations use the test-only pre-built certificates from the jersey project.
#
Remote List
The same list operation as before (Hive-Manifest-List) can be performed on the remote server as well, as long as Hive-Remote-Serve is still running.
Run Hive-Remote-List to try it - this will go through the HTTPS stack and perform the manifest listing remotely.
#
Remote Fetch & Push
The two tools fetch and push allow to fetch and push manifests along with all required objects from and to a remote hive.
Both operations are practically identical, just reversed. To demonstrate fetch, run Hive-Remote-Fetch and specify the manifest key you imported before. This will create a new (empty) hive (on first run) next to the one created by import (${workspace_loc}/runtime-hive-fetched) and fetch this manifest into that hive. Make sure that Hive-Remote-Serve is still running for this to work.
If you are interested, you can try to import another folder which shares some parts with the first one you imported. Due to the separation of content and location, each common file will be stored only once, regardless of it's location (name) in the tree. This will also enable fetch/push to transfer only missing objects.
#
FSCK
The FSCK (short for 'filesystem check') will check consistency of all objects and manifests in the BHive. Run Hive-FSCK to execute a FSCK on the sample BHive.
#
Delete
Manifests can be deleted from a BHive as well. Run Hive-Manifest-Delete to delete a manifest. Be sure to give the same manifest key as with Hive-Import.
Note that this operation only deletes the manifest, but not automatically all now-unreferenced objects from the object database. This is done by
#
Prune
Pruning is a cleanup operation which removes unreferenced objects from the storage. It is comparable to a git gc.
Run Hive-Prune after running Hive-Manifest-Delete to see the effects of pruning remaining objects. If you had only one manifest and deleted that, the result should be that the objects directory in the hive contains no files anymore (only empty directories).
#
TreeSnapshot & Co.
The ScanOperation allows to fetch a TreeSnapshot of a MANIFEST root tree. This allows to recursively retrieve all available/relevant information about a MANIFEST. This includes a listing of TREE, BLOB, MREF, missing/damaged objects, etc.
The TreeDiff allows to compare two TreeSnapshot objects. It will produce a TreeElementDiff for each element which is different in the two snapshots. This diff is based on the type and checksum of the according path entries in the snapshots. There is no actual content diff, but it is 'ease' to build one based on the available information.